Skip to main contentTL;DR
A SPQR cluster consists of the following components:
-
Shard: each shard contains a subset of the sharded data. This is a typical PostgreSQL cluster with a master and replicas.
-
Router: it acts as a query router, providing an interface between client applications and shards.
-
Coordinator: it stores metadata and manages the SPQR cluster.
Cluster Components
What does a typical application look like? Backends connect to a PostgreSQL cluster in some way. We assume that replication is configured in the cluster and backups are performed regularly. Writing requests come mainly to replicas, while reading and writing is done to the master.
We had the idea that we could put a proxy between the backends and the PostgreSQL clusters. The proxy would receive requests, determine which shard the request should be sent to, wait for a response from that shard, and then return the result to the backend.
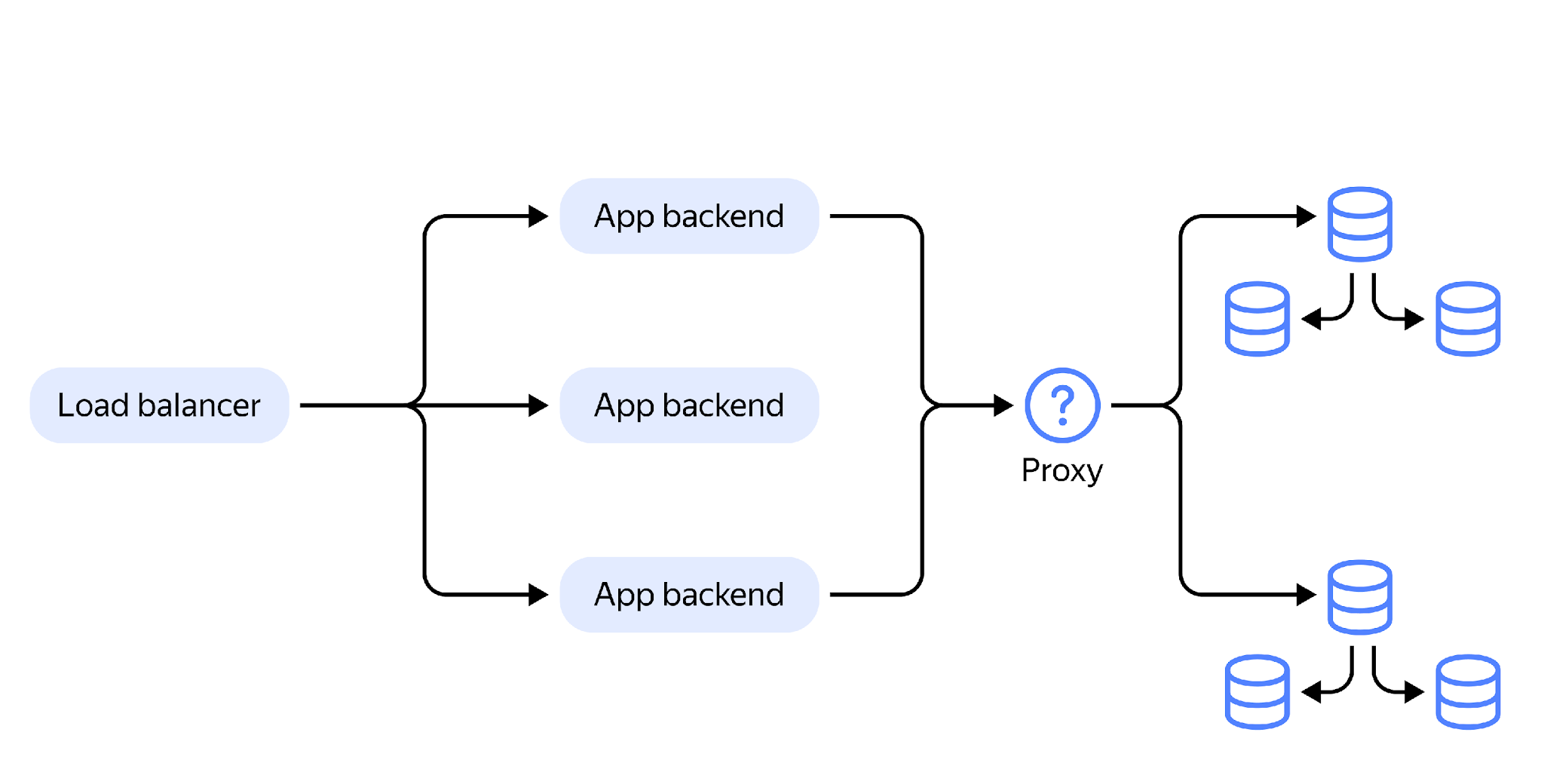 Actually, this is what we did. This thing is called the SPQR Router.
Actually, this is what we did. This thing is called the SPQR Router.
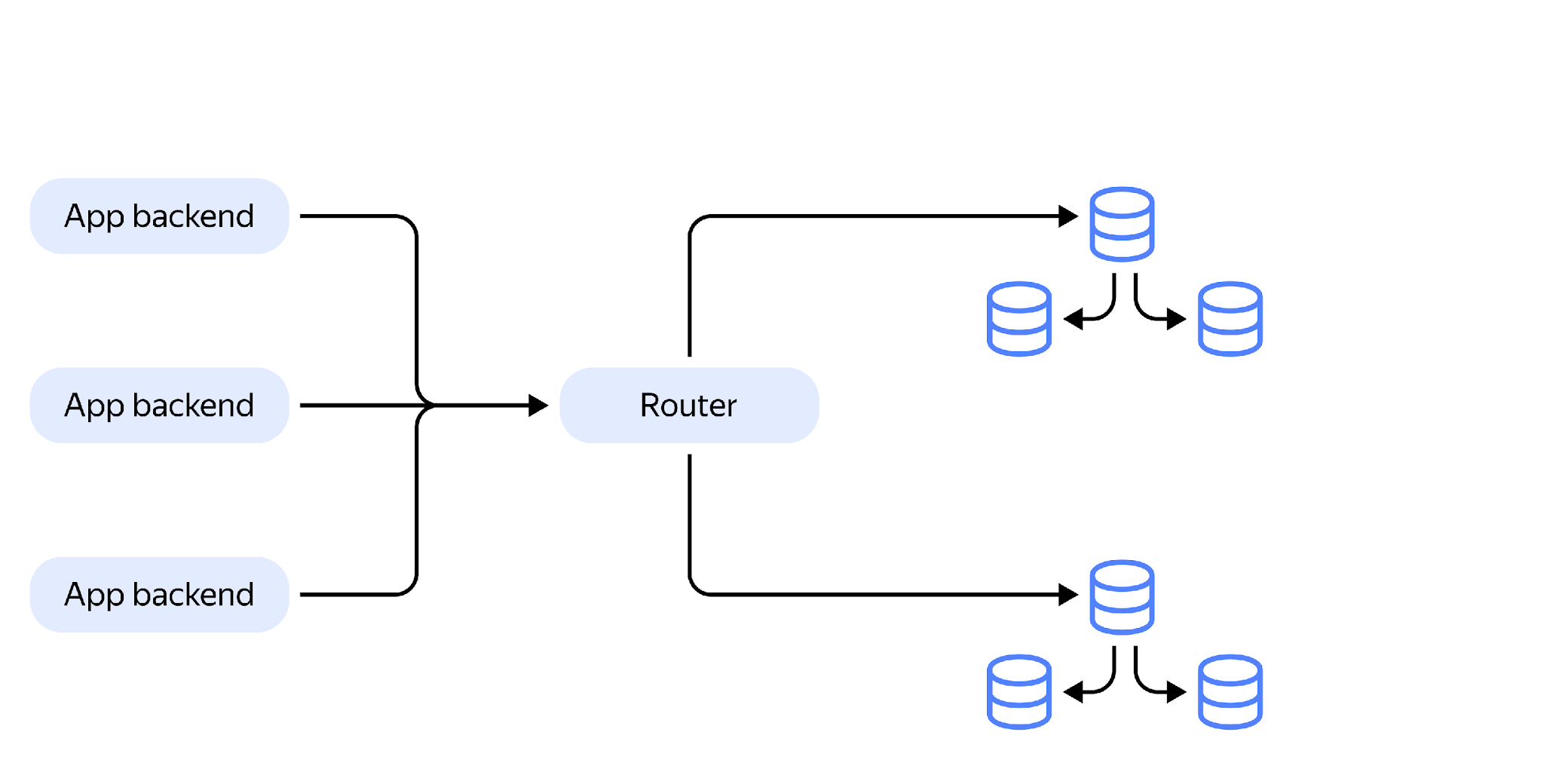 The router works using the PostgreSQL protocol, so the application doesn’t even realize that it’s communicating with a Golang application, not a regular PostgreSQL cluster. Due to this, we achieve a relatively high performance per one router.
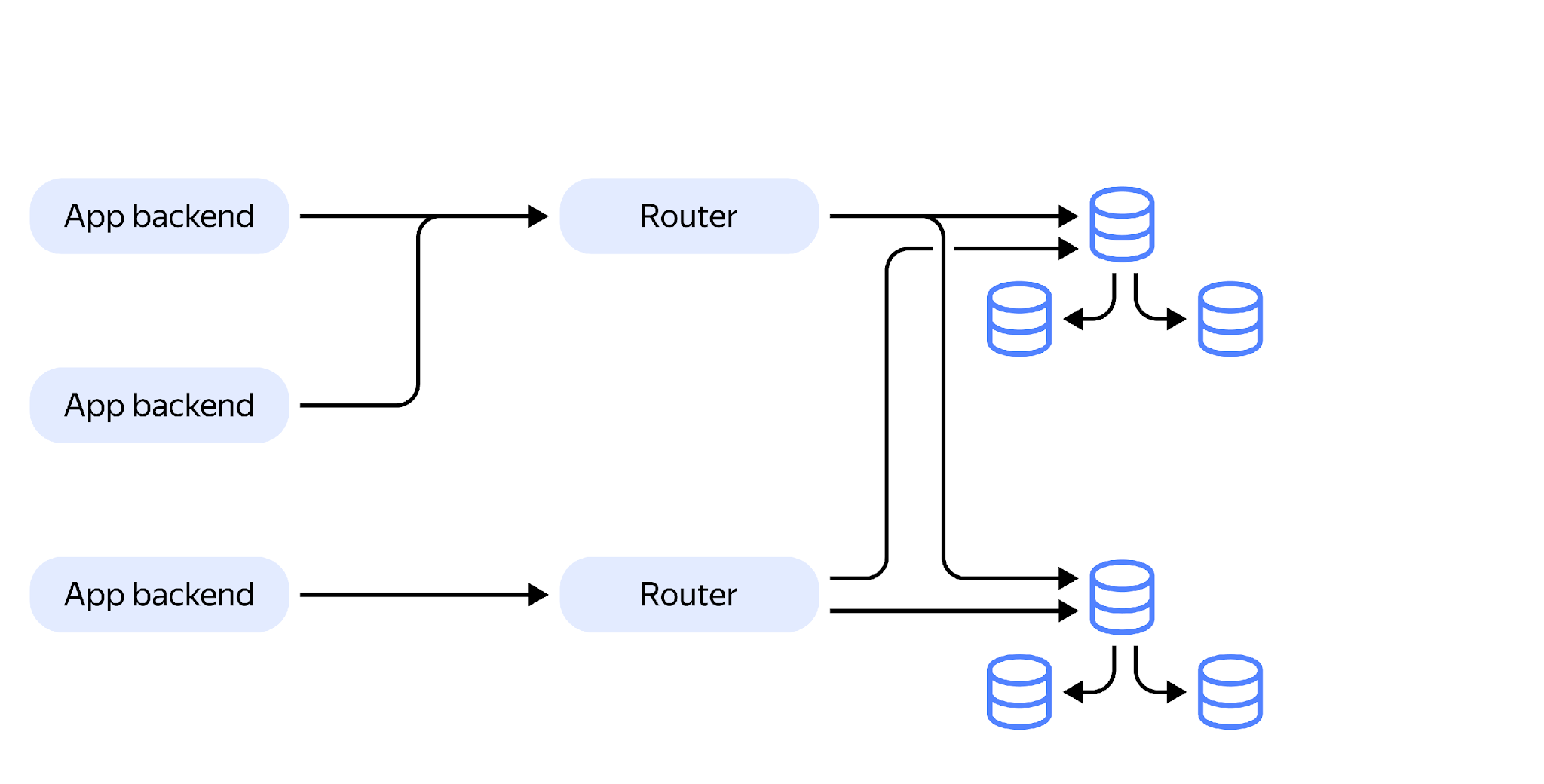
Clearly, in this configuration, the router is a bottleneck and a single point of failure. Therefore, we have designed a system where many routers can work in parallel. In fact, thousands of routers operating in parallel should not be a problem.
The router works using the PostgreSQL protocol, so the application doesn’t even realize that it’s communicating with a Golang application, not a regular PostgreSQL cluster. Due to this, we achieve a relatively high performance per one router.
Clearly, in this configuration, the router is a bottleneck and a single point of failure. Therefore, we have designed a system where many routers can work in parallel. In fact, thousands of routers operating in parallel should not be a problem.
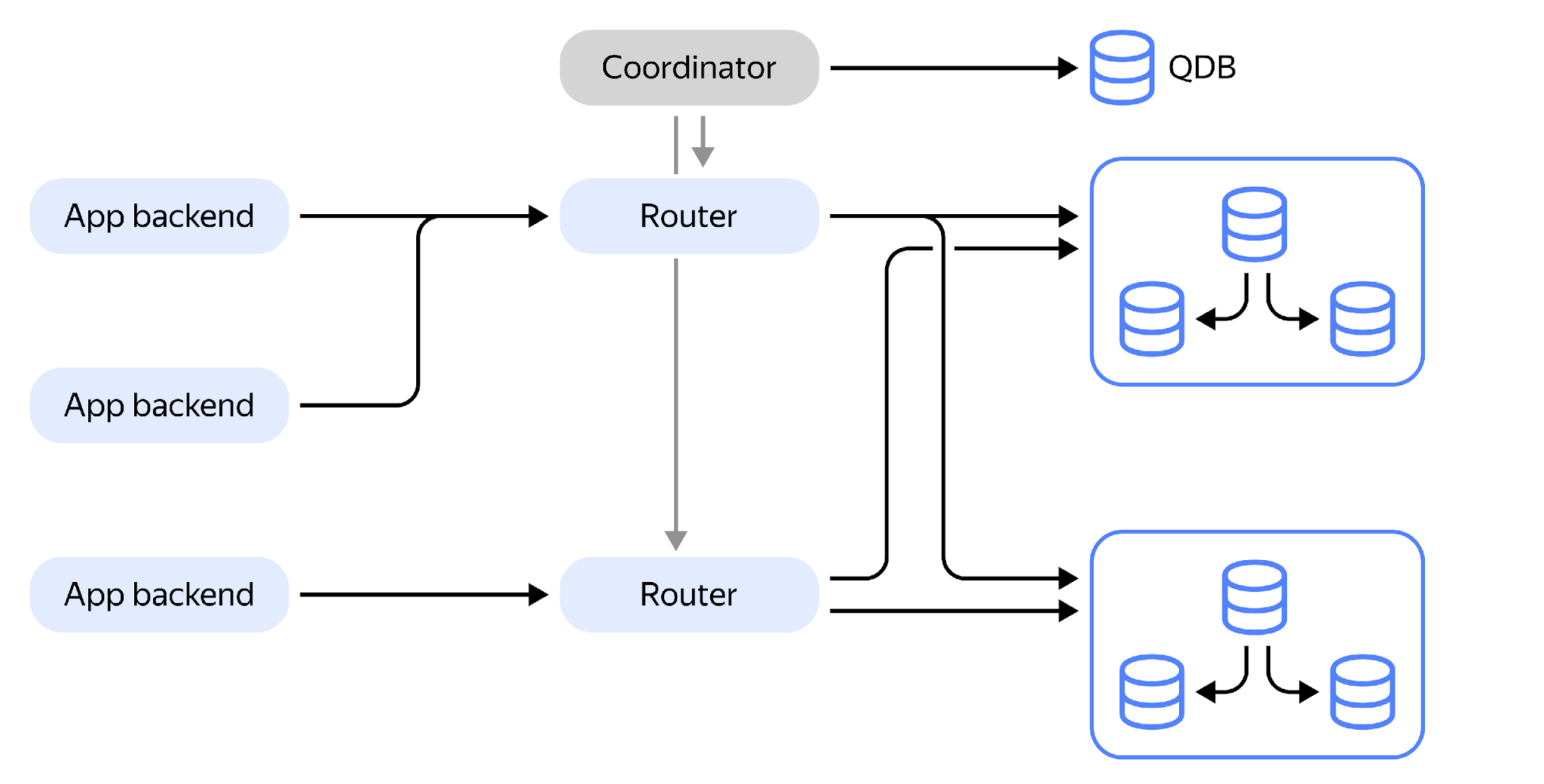
 But in order for routers to have the same metadata, we need to store this information somewhere. We store it in QDB, which is an regular etcd cluster. Metadata changes are performed by the SPQR Coordinator, so the coordinator makes sure the routers have the same information.
But in order for routers to have the same metadata, we need to store this information somewhere. We store it in QDB, which is an regular etcd cluster. Metadata changes are performed by the SPQR Coordinator, so the coordinator makes sure the routers have the same information.